[DB] 인덱스
인덱스 (Index)
인덱스는 데이터베이스에서 기본 개념 중 하나이다. 인덱스에 대해서 질문을 스스로 던지고 대답하며 정리한다. MySQL의 InnoDB를 기준으로 설명한다.
인덱스는 무엇이고, 왜 쓰는가
어떤 책 맨 뒤에, 특정 단어가 어디에 등장하는지 쪽수를 정리한 “색인(index)” 파트를 본 적이 있을 것이다. 인덱스도 같다. 색인이 어떤 단어가 등장하는 곳을 빠르게 찾아내기 위한 수단이듯이, DB에서 인덱스는 데이터를 빠르게 찾아내기 위한 수단이다.
B-tree? B+tree?
MySQL의 InnoDB 인덱스는 B+tree 자료구조를 사용한다.
B-tree는 일반적으로 알고있는 이진 탐색 트리와 유사하지만 balanced하다는 차이점이 있다. balanced하다는 것은 균형 잡혀있다는 뜻으로 높이가 한 쪽으로 치우치지 않음을 의미한다. B-tree에 삽입 또는 삭제할 때 트리의 균형을 맞추기 위해 특별한 과정이 추가된다.
B-tree는 최악의 경우에도 검색의 시간복잡도는 $ O(logN) $이다.
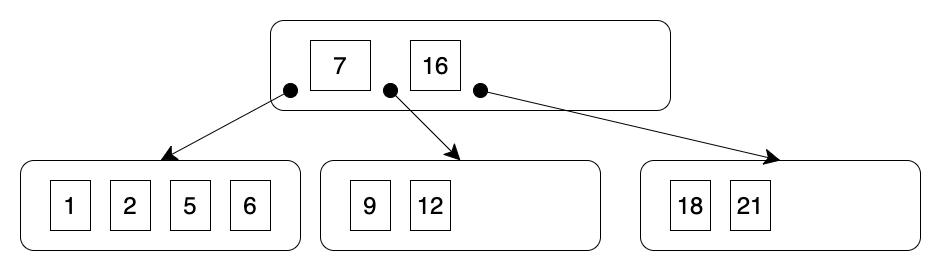 B-tree 예시
B-tree 예시
B+tree는 B-tree의 확장판이다. 차이점은 실제 레코드(데이터)들은 가장 하위 레벨에 정렬되어 있다는 점이다. B-tree에서 각 노드에 키(key)와 데이터(data)가 함께 저장되었다면, B+tree의 노드는 키만 저장하고 있다. 데이터는 리프 노드에 있고 이들은 LinkedList로 연결되어 있다.
B-tree와 B+tree의 차이점을 정리하면 다음과 같다.
- B+tree의 노드는 키만 저장하기 때문에, 한 노드에 저장할 수 있는 키(자식)의 수가 증가한다. 이는 검색에 필요한 I/O 동작 횟수를 줄이는 효과가 있다.
- B-tree는 모든 데이터가 리프 노드에 있지 않기 때문에 모든 데이터를 확인하기 위해 모든 노드에 방문해야 하지만, B+tree는 리프 노드의 선형탐색이 가능하다.
아래 이미지는 author_id가 4인 레코드(row)를 찾는 과정이다.
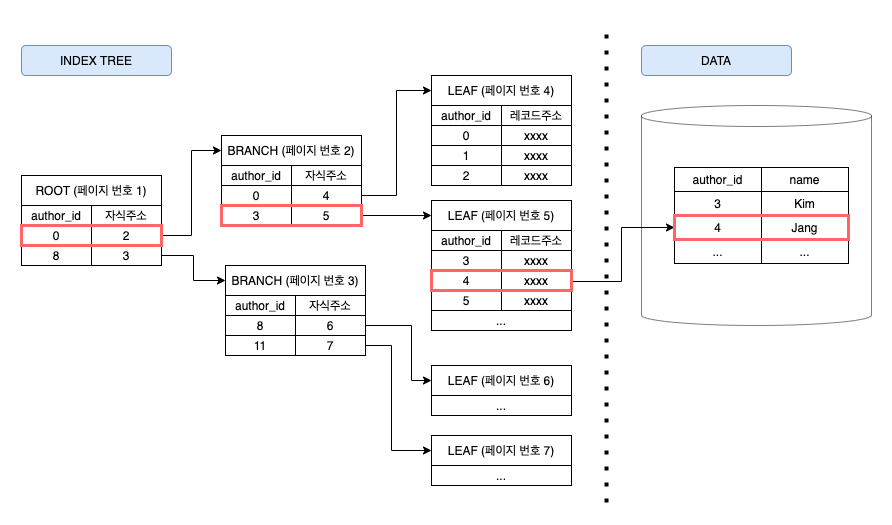 B+tree 인덱스 검색 예시
B+tree 인덱스 검색 예시
페이지
위 이미지에 쓰여있듯이, 데이터를 저장하는 기본단위는 페이지(또는 블록)이다. InnoDB의 인덱스 페이지 단위는 16KB이다.
어떤 칼럼의 인덱스를 생성해야할까?
가능한 많은 레코드를 구분하는 칼럼을 선택하는 것이 좋다. 그 정도를 나타내는 것이 카디널리티(Cardinality)이다. 예를 들어, 사람의 성별은 평균적으로 50% 밖에 걸러내지 못하므로 카디널리티가 낮다고 하고, 주민등록번호는 사람마다 유일하므로 카디널리티가 높다고 한다.
여러 칼럼으로 인덱스를 생성한다해도, 카디널리티가 높은순으로 구성하는게 성능이 뛰어나다.
MySQL 문서에서 흥미로운 글을 발견했다. 옵티마이저가 인덱스를 사용할지 테이블 스캔을 할지를 결정 하는 것은, 한 때는 인덱스가 테이블의 30% 이상을 구분할 수 있는지에 따라 결정했지만, 이제는 고정 백분율이 아니라 다양한 요인(테이블 크기, 행의 개수, I/O 블록 크기 등)을 기반으로 추정한다고 한다.
Each table index is queried, and the best index is used unless the optimizer believes that it is more efficient to use a table scan. At one time, a scan was used based on whether the best index spanned more than 30% of the table, but a fixed percentage no longer determines the choice between using an index or a scan. The optimizer now is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size. - 출처: https://dev.mysql.com/doc/refman/8.0/en/where-optimization.html
인덱스를 사용해보자
MySQL에서 인덱스는 PRIMARY KEY, UNIQUE, INDEX, FULLTEXT를 말한다.
테이블을 만들면서 인덱스를 생성할 수도 있고, 이미 만들어진 테이블에 대해서 인덱스를 생성할 수 있다.
1
2
3
4
5
6
7
8
9
10
-- 'id'가 기본키인 'members' 테이블을 생성한다.
CREATE TABLE `members` (
`id` INT AUTO_INCREMENT,
`first_name` VARCHAR(50) NOT NULL,
`last_name` VARCHAR(50) NOT NULL,
`email` VARCHAR(100) NOT NULL,
`birthdate` DATE NOT NULL,
`added` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(`id`)
);
1
2
3
4
5
6
7
8
-- 'email'에 대한 인덱스를 생성한다.
CREATE INDEX IDX_MEMBERS_EMAIL ON members (email);
-- 여러 칼럼에 대한 인덱스를 생성할 수도 있다.
ALTER TABLE members ADD INDEX IDX_MEMBERS_NAME (first_name, last_name);
-- 인덱스를 삭제한다.
ALTER TABLE members DROP INDEX IDX_MEMBERS_NAME;
인덱스가 생성한 칼럼을 조건절에 걸어서 조회하면 인덱스를 사용하는 것이다.
1
2
3
SELECT *
FROM members
WHERE id = 777;
인덱스를 사용하고 있는건가? - EXPLAIN
인덱스를 사용하는지 보려면 쿼리 앞에 EXPLAIN을 사용하여 실행계획을 보면 된다.
1
2
3
4
EXPLAIN
SELECT *
FROM members
WHERE id = 777;

EXPLAIN의 결과 의미는 MySQL 문서에 자세히 나와있다.
위 결과를 간단히 말하자면 “단순 조회이며, members 테이블에서, 기본 키를 사용하여, 단 하나의 행을 읽었다” 정도겠다.
좀 더 복잡한 쿼리를 봐보자.
테스트를 위해 새로운 테이블 authors와 posts를 만들었다.
테이블에 데이터를 채워주기 위해, 더미 데이터를 생성해주는 filldb라는 홈페이지를 이용했다.
authors 테이블은 5천 개, posts 테이블은 10만 개의 데이터를 가진다.
1
2
3
4
5
6
7
EXPLAIN
SELECT posts.title, authors.first_name, posts.date
FROM posts join authors
on posts.author_id = authors.id
WHERE posts.date > date('2020-01-01')
ORDER BY posts.date desc
LIMIT 10;

이전과 비슷하지만 테이블이 2개일 뿐이다.
“authors 테이블과 조인하면서 기본키를 이용해 한 개의 행을 읽고, posts 테이블에서 where 절 조건에 의해 풀 스캔하고, 정렬했다”로 해석된다.
한 개의 행을 읽었다는 건 키에 의해서 구분되는 행이 단 한 개라는 것이다.
MySQL 문서 중 Using filesort와 관한 글이 있는데, 쿼리를 더 빠르게 하고 싶다면 Using filesort를 주의하라고 한다.
If you want to make your queries as fast as possible, look out for Extra column values of Using filesort and Using temporary. - 출처: https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-extra-information
그렇다면, WHERE 절에서도 사용하고 ORDER BY 절에서도 사용하는 date 칼럼의 인덱스를 만들고 다시 시도해보자.
1
CREATE INDEX IDX_POSTS_DATE ON posts (date);

첫 행이 많이 달라진 것을 볼 수 있다. “인덱스를 통해 검색하며, 옵티마이저가 내림차순 인덱스 스캔을 했다”는 의미이다.
인덱스를 사용하긴 했지만 레코드(행) 개수가 충분하지 않으면 그 차이를 체감할 수 없을 것이다.(현재 posts 테이블의 행 개수는 10만이다)
다른 블로그 글을 보면 약 1,000만 개의 레코드로 테스트하는데, 그 환경을 구성하는 적당한 방법을 찾지 못했다.
만약 실제로 성능 테스트를 해야한다면 대용량 데이터를 넣을 방법을 찾아야 할 것이다.
인덱스가 정말 효과가 있는건가? - EXPLAIN ANALYZE
MySQL 8.0.18에 추가된 기능으로 EXPLAIN ANALYZE을 사용하면 옵티마이저의 기대값과 실제 실행이 얼마나 맞는지에 대한 정보를 보여준다.
이 기능을 사용하여 인덱스를 생성 전과 후가 얼마나 달라졌는지 확인할 수 있다.
1
2
3
4
5
6
7
EXPLAIN ANALYZE
SELECT posts.title, authors.first_name, posts.date
FROM posts join authors
on posts.author_id = authors.id
WHERE posts.date > date('2020-01-01')
ORDER BY posts.date desc
LIMIT 10;
1
2
3
4
5
6
7
# date 칼럼에 대한 인덱스 생성 전
-> Limit: 10 row(s) (cost=28351.95 rows=10) (actual time=37.262..37.278 rows=10 loops=1)
-> Nested loop inner join (cost=28351.95 rows=97778) (actual time=37.261..37.276 rows=10 loops=1)
-> Sort: posts.`date` DESC (cost=10426.80 rows=97778) (actual time=37.243..37.244 rows=10 loops=1)
-> Filter: (posts.`date` > <cache>(cast('2020-01-01' as date))) (cost=10426.80 rows=97778) (actual time=0.032..33.226 rows=3410 loops=1)
-> Table scan on posts (cost=10426.80 rows=97778) (actual time=0.027..25.785 rows=100000 loops=1)
-> Single-row index lookup on authors using PRIMARY (id=posts.author_id) (cost=0.25 rows=1) (actual time=0.003..0.003 rows=1 loops=10)
1
2
3
4
5
# date 칼럼에 대한 인덱스 생성 후
-> Limit: 10 row(s) (cost=2728.26 rows=10) (actual time=0.944..0.959 rows=10 loops=1)
-> Nested loop inner join (cost=2728.26 rows=3410) (actual time=0.943..0.958 rows=10 loops=1)
-> Index range scan on posts using IDX_POSTS_DATE, with index condition: (posts.`date` > <cache>(cast('2020-01-01' as date))) (cost=1534.76 rows=3410) (actual time=0.933..0.936 rows=10 loops=1)
-> Single-row index lookup on authors using PRIMARY (id=posts.author_id) (cost=0.25 rows=1) (actual time=0.002..0.002 rows=1 loops=10)
인덱스 생성 전과 후를 비교해보면, cost가 1/10으로 줄었고(28351.95 -> 2728.26), actual time 37.278에서 0.959로 대폭 감소했다. 인덱스 생성 전에는 테이블 스캔과 정렬 과정이 많은 부분을 차지했었는데, Index range scan을 통해 cost와 time이 확 줄어들었다.
실제 1,000만 건의 레코드는 없더라도, EXPLAIN ANALYZE를 통해 간접적으로 인덱스의 효능을 확인할 수 있었다.


댓글 남기기